
magicplan-AI, a journey into the wonderful world of Deep Learning (Part 3/3)
Inside magicplan
4 min read

Share
In part 2, we showed how you could reach a good level detection accuracy on a Deep Learning model running on powerful GPU, when you have the right expertise on Deep Learning training. Unfortunately, this is not enough when you want to implement the feature on a smartphone and have to deal with really limited hardware resources both in terms of memory and computing power.
Embedding the feature into a smartphone
Previous work allowed to design and train a “good enough” door / window object detection model. However, even just for the inference part, this architecture can only run on powerful NVIDIA GPU. It is incompatible with the smartphone limited hardware resources, both in terms of memory requirements and processing time. This is a huge problem that kept us stuck for a while.
The remote approach
At first, the contemplated solution was to offload the GPU computation on the cloud.
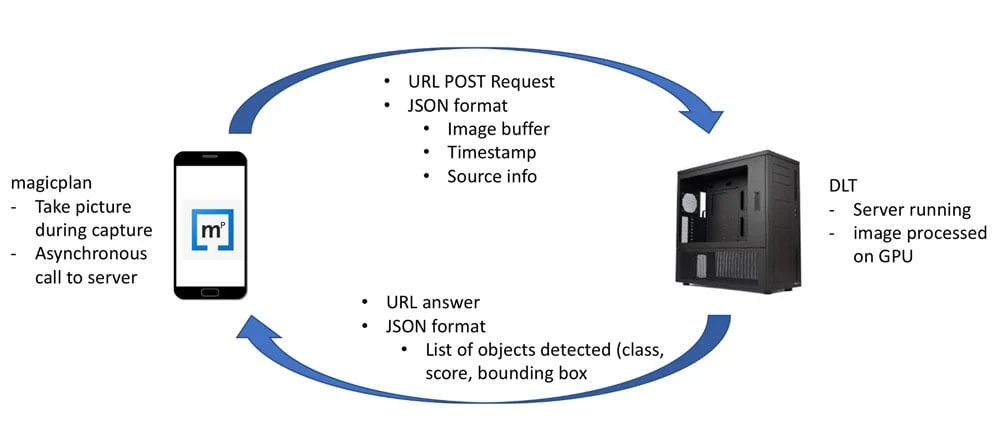
Remote GPU based solution
The main advantage of this approach is that the server has the required GPU memory and computation power to run properly the model. So, this solution is available day one.
However, 3 factors made this approach problematic:
magicplan is designed to run both online and offline. Relying on an remote connection for windows / doors detection would change this paradigm,
the upload and download durations create an unwanted and unpredictable lag that can be really annoying during the real-time capture session,
there was an uncertainty in the cost of deploying GPU servers on the cloud in order to scale with the potential demand, once in production.
Nevertheless, the approach was very useful to “simulate”, locally on a private network and in real capture conditions, the reliability of the model and validate that the user experience was acceptable. Eventually, the combination of 3 solutions allowed us to overcome this critical barrier:
Applying quantising approach to reduce memory footprint through lowering floating precision,
Applying the Teacher / Student approach to our model to “shrink” it to an acceptable memory size, while keeping the same detection accuracy,
Moving part of the model from the TensorFlow standard framework to the Apple CoreML accelerated framework to optimise computing performance on the smartphone.
Applying quantising approach
Quantisation is the idea of moving from floating point to integer arithmetic, thus saving in memory and computation time. This was a quick win as TensorFlow offers some tools to revisit a given model to perform quantisation very easily.
More on the topic: Zhouhan Lin, Matthieu Courbariaux, Roland Memisevic, and Yoshua Bengio. Neural networks with few multiplications. CoRR, abs/1510.03009, 2015.
Applying the Teacher / Student approach
We have to thank the MILA laboratory with whom we collaborated in an IRAP funded initiative as they recommended us this approach as a way of shrinking the model and it worked! It was key to have MILA expertise guiding us on this solution, a solution we would have most likely not considered otherwise.
This advanced approach is quite fascinating. To make it short, it relies on the idea that small models are worse at generalising than large models during the training procedure. So, in order to have good training for a small model, it helps to have a large model “distilling” knowledge from its internal layers into some internal layers of the small model.
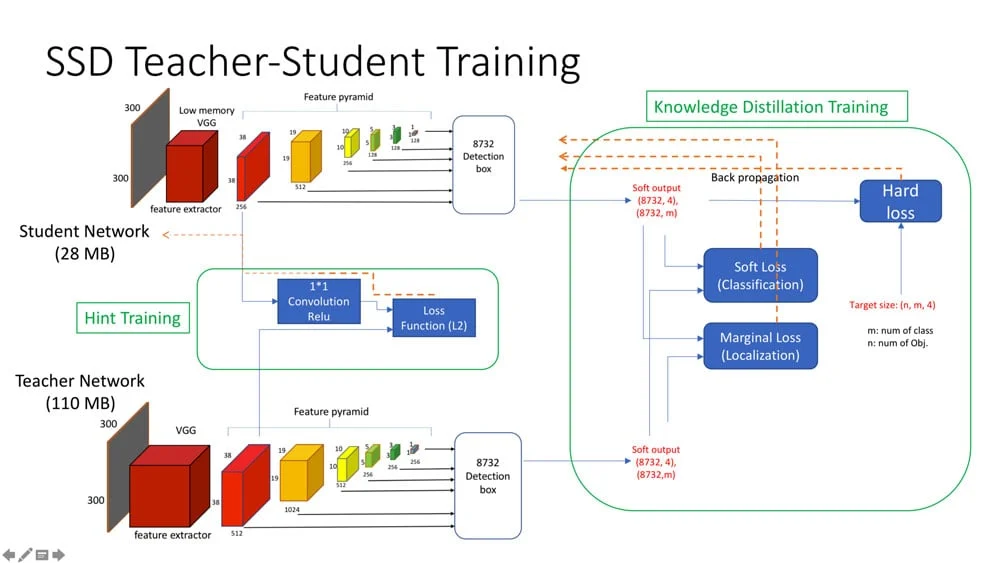
Teacher — Student implementation
More on the topic:
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. In ICLR, 2015.
Moving to Apple CoreML GPU accelerated framework
While Deep Learning frameworks on PC with GPU acceleration are quite mature, this is not true when it comes to porting these frameworks to iOS or Android:
Embedded versions of the main frameworks (like TensorFlow Mobile) are still in their early stages and not taking full advantage of the smartphone HW.
On the other end, there is Apple CoreM. CoreML is the official Apple Machine Learning framework for iOS, optimised for on-device performance. Unfortunately, nowadays, it only covers a limited subset of computation nodes implemented in TensorFlow.
In addition, there is still no standard interoperability format allowing one to port easily a model from one framework to another up to the embedded implementation, even if initiatives like ONNX or NNEF are making their way.
As a result, the only way to get the best on iOS is to manually refactor the full graph into several parts to easily port the relevant subgraph to CoreML. After all these operations, the resulting SSD model has the performance of the best R-CNN model validated on large GPU while occupying 14 MB and performing an inference in 250 ms on iPhone X. Quite an achievement!
Previous work allowed to design and train a “good enough” door / window object detection model. However, even just for the inference part, this architecture can only run on powerful NVIDIA GPU. It is incompatible with the smartphone limited hardware resources, both in terms of memory requirements and processing time. This is a huge problem that kept us stuck for a while.
The remote approach
At first, the contemplated solution was to offload the GPU computation on the cloud.
Remote GPU based solution
The main advantage of this approach is that the server has the required GPU memory and computation power to run properly the model. So, this solution is available day one.
However, 3 factors made this approach problematic:
magicplan is designed to run both online and offline. Relying on an remote connection for windows / doors detection would change this paradigm,
the upload and download durations create an unwanted and unpredictable lag that can be really annoying during the real-time capture session,
there was an uncertainty in the cost of deploying GPU servers on the cloud in order to scale with the potential demand, once in production.
Nevertheless, the approach was very useful to “simulate”, locally on a private network and in real capture conditions, the reliability of the model and validate that the user experience was acceptable. Eventually, the combination of 3 solutions allowed us to overcome this critical barrier:
Applying quantising approach to reduce memory footprint through lowering floating precision,
Applying the Teacher / Student approach to our model to “shrink” it to an acceptable memory size, while keeping the same detection accuracy,
Moving part of the model from the TensorFlow standard framework to the Apple CoreML accelerated framework to optimise computing performance on the smartphone.
Applying quantising approach
Quantisation is the idea of moving from floating point to integer arithmetic, thus saving in memory and computation time. This was a quick win as TensorFlow offers some tools to revisit a given model to perform quantisation very easily.
More on the topic: Zhouhan Lin, Matthieu Courbariaux, Roland Memisevic, and Yoshua Bengio. Neural networks with few multiplications. CoRR, abs/1510.03009, 2015.
Applying the Teacher / Student approach
We have to thank the MILA laboratory with whom we collaborated in an IRAP funded initiative as they recommended us this approach as a way of shrinking the model and it worked! It was key to have MILA expertise guiding us on this solution, a solution we would have most likely not considered otherwise.
This advanced approach is quite fascinating. To make it short, it relies on the idea that small models are worse at generalising than large models during the training procedure. So, in order to have good training for a small model, it helps to have a large model “distilling” knowledge from its internal layers into some internal layers of the small model.
Teacher — Student implementation
More on the topic:
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. In ICLR, 2015.
Moving to Apple CoreML GPU accelerated framework
While Deep Learning frameworks on PC with GPU acceleration are quite mature, this is not true when it comes to porting these frameworks to iOS or Android:
Embedded versions of the main frameworks (like TensorFlow Mobile) are still in their early stages and not taking full advantage of the smartphone HW.
On the other end, there is Apple CoreM. CoreML is the official Apple Machine Learning framework for iOS, optimised for on-device performance. Unfortunately, nowadays, it only covers a limited subset of computation nodes implemented in TensorFlow.
In addition, there is still no standard interoperability format allowing one to port easily a model from one framework to another up to the embedded implementation, even if initiatives like ONNX or NNEF are making their way.
As a result, the only way to get the best on iOS is to manually refactor the full graph into several parts to easily port the relevant subgraph to CoreML. After all these operations, the resulting SSD model has the performance of the best R-CNN model validated on large GPU while occupying 14 MB and performing an inference in 250 ms on iPhone X. Quite an achievement!
Lessons learnt
When it comes to embedding models in smartphones, the reality is that the embedded frameworks and interoperability tools are still in the early stages, in stark opposition with the experience we had with the POC on GPU powered PCs.
In addition, advanced Deep Learning training techniques are required to obtain good results. You need a Deep Learning specialised team to deal with these advanced training procedures as well as playing with interoperability and complex acceleration codes.
This is where a collaboration with top AI academic organisations can be decisive in choosing the right directions and options to reach the targets.
Conclusion
Our journey in Deep Learning has been an amazing but challenging experience. Truly, the 80 / 20 rule applies:
it is easy to get some encouraging results thanks to the availability of mature prototyping tools and off-the-shelf models at start,
when it comes to a real app, you are much more on your own for deploying the technology on a smartphone and dealing with advanced training techniques to produce smartphone constraints compatible models.
We are now in the beta phase of magicplan-AI. That means that the feature is live on magicplan 7.2 for iOS!
The purpose of this beta is to improve the training set as well as to understand better the user experience and identify what works and what needs to be changed. There is still some significant work to make it an official feature but we believe that eventually AI will become part of the core of magicplan, just like AR has been in magicplan for the last 5 years.
Whether it is through an extension of its uage (to electrical outlets or corner detection), or by implementing a continuous training approach to the models, Sensopia Research team has a lot of exciting Deep Learning work ahead!
And to that end, we are hiring!
Acknowledgments
I want to thank Jonathan Aigrain and Vahid Ettehadi, our two top research engineers for their outstanding work at making magicplan-AI happen. It is their achievement first.
I also want to thank Sylvain Laroche from the National Research Council Canada for the trust he has always demonstrated in Sensopia capabilities. The NRCC has helped us at critical stages of the company over the years, allowing our small structure to achieve ambitious projects while mitigating the financial risks.
Finally, our gratitude goes to Mike Pieper (MILA R&D and Technological Transfer Team) for all the good advices he gave us. That made the difference at the end.
Our journey in Deep Learning has been an amazing but challenging experience. Truly, the 80 / 20 rule applies:
it is easy to get some encouraging results thanks to the availability of mature prototyping tools and off-the-shelf models at start,
when it comes to a real app, you are much more on your own for deploying the technology on a smartphone and dealing with advanced training techniques to produce smartphone constraints compatible models.
We are now in the beta phase of magicplan-AI. That means that the feature is live on magicplan 7.2 for iOS!
The purpose of this beta is to improve the training set as well as to understand better the user experience and identify what works and what needs to be changed. There is still some significant work to make it an official feature but we believe that eventually AI will become part of the core of magicplan, just like AR has been in magicplan for the last 5 years.
Whether it is through an extension of its uage (to electrical outlets or corner detection), or by implementing a continuous training approach to the models, Sensopia Research team has a lot of exciting Deep Learning work ahead!
And to that end, we are hiring!
Acknowledgments
I want to thank Jonathan Aigrain and Vahid Ettehadi, our two top research engineers for their outstanding work at making magicplan-AI happen. It is their achievement first.
I also want to thank Sylvain Laroche from the National Research Council Canada for the trust he has always demonstrated in Sensopia capabilities. The NRCC has helped us at critical stages of the company over the years, allowing our small structure to achieve ambitious projects while mitigating the financial risks.
Finally, our gratitude goes to Mike Pieper (MILA R&D and Technological Transfer Team) for all the good advices he gave us. That made the difference at the end.
Related Articles





© 2026 magicplan. Alle Rechte vorbehalten.
© 2026 magicplan. Alle Rechte vorbehalten.
© 2026 magicplan. Alle Rechte vorbehalten.