

magicplan-AI, a journey into the wonderful world of Deep Learning (Part 1/3)
Inside magicplan
5 min read

Share
Computer vision is undergoing a spectacular revolution thanks to AI advances, particularly in Deep Learning. Every day, a new article shows capabilities you could not imagine 5 years ago. Whether it comes from the GAFA teams or from the top labs’ spinoffs, it looks like AI for image understanding is making its way in the enterprise.
But what does this mean for a small company with more classical computer vision at the core of its product?
What does it take to do the big dive into Deep Learning? How robust is this new approach to production requirements such as accuracy and speed on a smartphone app?
My name is Pierre Pontevia. I am a founder and Chief Research Officer for magicplan. Today I would like to share with you our journey toward implementing a Deep Learning based feature into our app.
In this article, we will not discuss the Singularity, nor beating any Go master or the latest breakthroughs in Generative Networks. We will instead share the practical steps necessary for a team of engineers to take a Deep Learning feature out of the “lab” and embed it in an app used by millions of smartphone owners.
Quick introduction to magicplan
Part 1 — Developing a POC to assess feasibility
As head of a small research team in a small startup, my first duty is to ensure we are working on something impactful on the product. That means we need to identify quickly and at a minimal cost whether a potential innovative technology is worth being investigated or not.
A Proof of Concept (POC) is key to achieve this. By POC, we mean translating an approach / algorithm / solution described mostly in academic articles into some executable code that we will run to evaluate the performance of the algorithm under circumstances as close as possible to the end case we want to solve.
Several factors helped us to really quickly develop and evaluate the POC:
Almost all the tools and frameworks used to perform Deep Learning are open-source, lowering significantly the barrier of accessing a professional / reliable environment,
The academic world is very active in the field of “Deep Learning for Computer Vision” and researchers share what they develop with the community, simplifying drastically the work required to translate an idea into a code,
The GAFAs have done a tremendous job of structuring and sharing the most popular Deep Learning models with the AI community, accelerating the task of testing a particularly popular model on a specific sub-domain,
Data is key in Deep Learning. Fortunately, there are some large and free annotated databases available on the Internet for training models,
Deep Learning is computation-intensive. The good news is that Deep Learning hardware is getting cheaper.As an alternative, you can start using GPU on the cloud and avoid investments at the beginning (when you are not sure how promising the idea is).
Helped by these facilitators, we structured the POC in 4 main steps:
identifying the field of academic research covering our needs,
getting familiar with the most popular Deep Learning framework,
leveraging on-the-shell pre-trained relevant models from the model zoos available on the internet,
testing them on our specific challenge: the capturing of doors and windows.
The academic research field
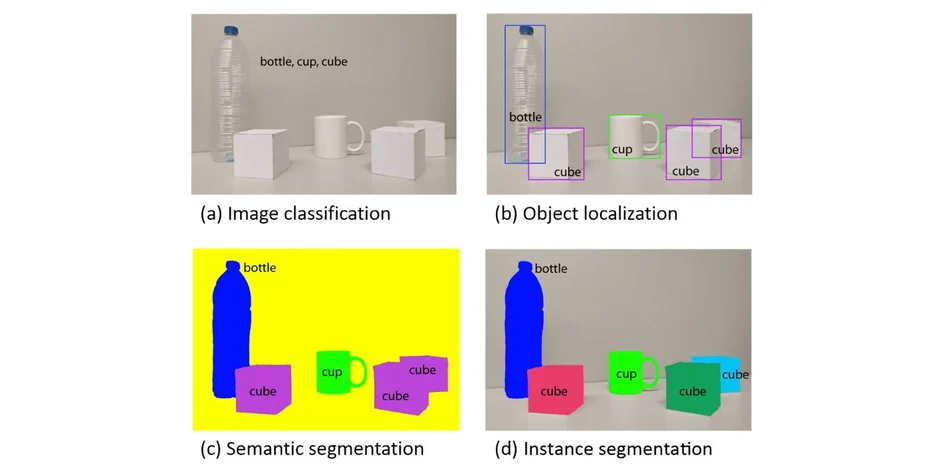
In our case, it was easy to identify ‘object detection (or localisation)’ as the research domain we wanted to dig in. Interestingly, ‘object localisation’ is just the second level in the scale of complexity of what you can understand in an image as described in the table below.
Deep Learning frameworks
TensorFlow (owned by Google) is the most used Deep Learning framework today. That means there is a high chance any work described in an article has been implemented or reproduced using TensorFlow. As a side note on the framework selection, popularity is an important criterion but not the only one. Ease of use and/or maturity in production tools are also important.
Accessing pre-trained models
The TensorFlow team maintains a Model Zoo in an additional repository. There you can find multiple python modules offering APIs to implement the most popular Deep Learning models, including object detection models. These models come with pre-trained configurations. The training has been done on available data sets such as COCO. That saved us time and developments in the early stages of the evaluation.
The ‘object detection’ implementation in the library offers the ability to use ‘Transfer Learning’ through fine-tuning. In this approach, you start with an existing model, pre-trained on millions of images (such as COCO dataset), and you re-train on a smaller set of images (a couple hundreds images are enough for early testing) of your sub-domain (windows and doors pictures taken from the interiors in our case).
This approach saved us the burden of two significant challenges during the POC:
the fact that usually, deep learning needs TONS of data in order to generalise correctly on a given problem. And it is quite unlikely that you have this volume of data available at the beginning of your investigation,
the fact that training on millions of images takes a lot of time (and money) if you do not have the proper hardware resources at hand. This is likely when you are a beginner in the world of Deep Learning.
The challenge of finding several thousands of already annotated images of doors and windows was overcome by the availability of the ImageNet training dataset.
ImageNet offers access to more than 16 millions images indexed with a semantic tree of over 35 000 different categories. By just selecting the images containing the keywords ‘door’ or ‘window’, we were able to gather around 3500 images, enough to do a proper “Transfer Learning” based training.
Testing on our use case
Keeping in mind the real-time constraints of the magicplan capture scenario, we chose to start with a simple and popular model called “SSD Inception V2” (more details in next part), to see how well it was at dealing with the task.
We re-trained the model with 3300 images split into a training dataset and a validation dataset as recommended for a proper training. The remaining 200 images were used as a test set to measure the progress of our different iterations.
In a matter of weeks, we were able to achieve a first acceptable level of performance with the trained model. Far from being perfect, the results were good enough to take the decision of investing more time and resources into the Deep Learning based object detection for windows and doors.
Lessons learnt
The main lesson of this first stage is that, when it comes to implementing features relying on validated Deep Learning techniques (such as object detection), you can and should use all the existing Deep Learning resources available on the Internet to maximise the efficiency of developing and testing your prototype.
That said, it is one thing to have a workable prototype showing the potential of the approach. It is another thing to make it part of an app downloaded by millions of users every day.
Coming next
In part 2 of 3, we will describe more in detail the work required to move from a prototype to a usable feature in term of performance.




